Robots.txt használatáról közérthetően-példákkal

A hatékony weboldal-menedzsment és a keresőoptimalizálás (SEO) érdekében elengedhetetlen annak kezelése, hogy a keresőmotorok feltérképező robotjai hogyan navigálnak az Ön webhelyén. Ez a robots.txt feladata, amely egy digitális kapuőrként működő fájl, és ezeket a robotokat a hozzáférhető és korlátozott területekre irányítja. Ez az útmutató alaposan feltárja a robots.txt működését, beleértve a szintaxisát, a legjobb gyakorlatait és a SEO előnyeinek maximalizálására szolgáló stratégiákat.
Rövid kivonat
A Robots.txt szabályozza, hogy a keresőmotorok feltérképező robotjai (például a Googlebot) hogyan férnek hozzá az Ön weboldalához, megakadályozva a duplikált tartalom indexelését, megtakarítva a feltérképezési költségvetést, és rejtve tartva a privát területeket. A robots.txt fájl megfelelő konfigurálása olyan direktívák használatával, mint a Disallow, Allow és Sitemap, kulcsfontosságú a jó SEO és a weboldal egészsége szempontjából. Használja bölcsen a webhely keresőmotorok általi feltérképezésének optimalizálására és az indexelés javítására.
Megvizsgáljuk a robots.txt alapvető fogalmait, a direktívák szintaxisát, a haladó szempontokat, a megvalósítás lépéseit, a legjobb gyakorlatokat, a gyakori hibákat, a hibaelhárítást és a gyakran ismételt kérdéseket.
A Robots.txt alapjainak megértése
Hogyan működik a Robots.txt?
Amikor egy keresőmotor feltérképező robotja, mint például a Googlebot vagy a Bingbot, meglátogatja az Ön weboldalát, az első dolog, amit általában keres, a robots.txt fájl. Ha talál ilyet, elolvassa az utasításokat, mielőtt továbblépne a webhely többi részének feltérképezésére. Ezek az utasítások, más néven direktívák, megmondják a feltérképezőnek, hogy mely URL-ekhez van engedélye vagy tilos hozzáférnie. Ha nem található robots.txt fájl, a feltérképező általában feltételezi, hogy a weboldal minden részét feltérképezheti.
Fontos megérteni, hogy a robots.txt egy irányelvrendszer, nem pedig egy bolondbiztos biztonsági intézkedés. Bár a legtöbb jó hírű keresőmotor-feltérképező tiszteletben tartja ezeket a direktívákat, a rosszindulatú robotok vagy más típusú weboldal-adatgyűjtők figyelmen kívül hagyhatják azokat. Ezért soha ne támaszkodjon a robots.txt-re érzékeny információk védelmében.
A Robots.txt SEO szempontú használatának előnyei
- A duplikált tartalom indexelésének megakadályozása: A keresőmotorok néha ugyanannak a tartalomnak több verzióját is indexelhetik, például nyomtatóbarát oldalakat vagy különböző URL-paraméterekkel rendelkező oldalakat. Ha a robots.txt fájlban letiltja a hozzáférést ezekhez a duplikált verziókhoz, segíthet a keresőmotoroknak a fő, kiváló minőségű tartalom indexelésére összpontosítani.
- A feltérképezési költségvetés megőrzése: A keresőmotorok egy bizonyos "feltérképezési költségvetést" különítenek el minden weboldal számára, amely azt jelenti, hogy egy adott időkereten belül hány oldalt fognak feltérképezni. Ha letiltja a hozzáférést a kevésbé fontos oldalakhoz (például belső keresési eredmények vagy tesztkörnyezetek), biztosítja, hogy a keresőmotorok feltérképezői az értékes idejüket a legfontosabb, felhasználóknak szánt tartalom feltérképezésére és indexelésére fordítsák.
- A hozzáférés szabályozása bizonyos területekhez: Lehetnek olyan részei a webhelyének, amelyek nem nyilvánosak vagy nem indexelhetők, például adminisztrációs irányítópultok, belső eszközök vagy fejlesztői környezetek. A robots.txt lehetővé teszi, hogy megakadályozza a keresőmotorok feltérképezőinek hozzáférését ezekhez a területekhez, így azok nem jelennek meg a keresési eredmények között.
- A szerver terhelésének kezelése: Ha webhelye nagy forgalmat bonyolít le, vagy korlátozottak a szerver erőforrásai, a robots.txt segítségével visszatarthat bizonyos robotokat az agresszív feltérképezéstől, ezzel is segítve a szerver túlterhelésének megelőzését.
A Robots.txt alapvető formátuma
A robots.txt fájl egy egyszerű szöveges fájl, amelynek pontosan "robots.txt" a neve, és a webhely gyökérkönyvtárában kell elhelyezkednie (pl. https://www.sajatdomainom.hu/robots.txt). A fájl minden direktívája külön sorban jelenik meg, és egy meghatározott szintaxist követ. Az alapvető szerkezet egy User-agent (a direktíva által érintett robot neve) megadását foglalja magában, amelyet egy vagy több direktíva követ, mint például a Disallow vagy az Allow.
A Robots.txt alapvető direktívái: Szintaxis és példák
Íme a robots.txt fájlban leggyakrabban használt alapvető direktívák:
User-agent: Ez a direktíva azonosítja azt a konkrét webes feltérképezőt vagy robotot, amelyre a következő szabályok vonatkoznak. Megcélozhat konkrét robotokat, vagy használhat egy csillagot (*) az összes robot megcélzásához.- Példa: A Googlebot megcélzásához:
User-agent: Googlebot - Példa: A Bingbot megcélzásához:
User-agent: Bingbot - Példa: Az összes robot megcélzásához:
User-agent: *
- Példa: A Googlebot megcélzásához:
Disallow: Ez a direktíva azt mondja a megadott felhasználói ügynök(ök)nek, hogy ne férjenek hozzá a megadott útvonalhoz.- Példa: Az összes robot blokkolása az /admin/ mappából:
Ez megakadályozza, hogy az összes keresőmotor-feltérképező hozzáférjen aUser-agent: * Disallow: /admin//admin/könyvtárban található fájlokhoz vagy alkönyvtárakhoz.
- Példa: Az összes robot blokkolása az /admin/ mappából:
Allow: Ez a direktíva engedélyezi a megadott felhasználói ügynök(ök) számára, hogy hozzáférjenek egy adott útvonalhoz, még akkor is, ha az egy egyébként tiltott könyvtáron belül található. Vegye figyelembe, hogy nem minden keresőmotor támogatja teljes mértékben azAllowdirektívát, ezért óvatosan használja.- Példa: A Googlebot számára engedélyezett hozzáférés egy adott fájlhoz egy tiltott mappán belül:
Ebben az esetben aUser-agent: Googlebot Disallow: /kepek/ Allow: /kepek/specifikus-kep.jpg/kepek/mappában lévő összes fájl általában tiltott a Googlebot számára, kivéve a/kepek/specifikus-kep.jpgfájlt.
- Példa: A Googlebot számára engedélyezett hozzáférés egy adott fájlhoz egy tiltott mappán belül:
Sitemap: Ez a direktíva megadja az Ön XML oldaltérkép(ei)nek a helyét, ami segít a keresőmotoroknak felfedezni és feltérképezni a webhelyén található összes fontos oldalt. TöbbSitemapdirektívája is lehet a robots.txt fájlban.- Példa: Az XML oldaltérképére való hivatkozás:
Sitemap: https://www.sajatdomainom.hu/sitemap.xml - Ha több oldaltérképe van:
Sitemap: https://www.sajatdomainom.hu/sitemap_index.xml Sitemap: https://www.sajatdomainom.hu/sitemap_products.xml
- Példa: Az XML oldaltérképére való hivatkozás:
Egyéb direktívák
Host: Ezt a direktívát a webhely preferált domainjének megadására használták, különösen régebbi keresőmotorok esetében. A modern keresőmotorok általában kanonikus címkékkel és más módszerekkel kezelik ezt, így aHostmanapság kevésbé elterjedt.- Példa:
Host: www.sajatdomainom.hu
- Példa:
Crawl-delay: Ez a direktíva egy adott robot által küldött feltérképezési kérelmek közötti késleltetést javasol másodpercekben. Ez hasznos lehet a szerver túlterhelésének megakadályozására agresszív feltérképezők esetén. Azonban nem minden keresőmotor tartja tiszteletben ezt a direktívát, és a Google ehelyett a Google Search Console-ban található feltérképezési sebesség beállításainak használatát javasolja.- Példa:
User-agent: * Crawl-delay: 5
- Példa:
Clean-param: Ez a direktíva azt mondja a keresőmotoroknak, hogy hagyják figyelmen kívül bizonyos URL-paramétereket, hogy megakadályozzák az ezen paraméterek által okozott duplikált tartalom indexelését (pl. követési azonosítók). A Google elavulttá nyilvánította ezt a direktívát, és általában jobb a paraméterkezelést a Google Search Console-ban végezni.- Példa:
Clean-param: sessionid /termekek/index.php
- Példa:
Haladó Robots.txt direktívák és szempontok
Bár az alapvető direktívák a legtöbb általános felhasználási esetet lefedik, léteznek kevésbé gyakran használt direktívák és szempontok is:
Request-rate: Ez a direktíva azt javasolja, hogy egy feltérképező percenként legfeljebb hány kérést küldjön. A jelentős keresőmotorok nem támogatják széles körben.Cache-delay: Ez a direktíva azt javasolja, hogy a feltérképezők mennyi ideig várjanak egy oldal újrafeltérképezése előtt. Nem támogatott széles körben.Visit-time: Ez a direktíva a nap meghatározott időpontjait javasolja, amikor a feltérképezők meglátogassák a webhelyet. Nem támogatott széles körben.Robot-version: Ez a direktíva a használt Robots Exclusion Protocol verzióját adja meg. A gyakorlatban ritkán használják.
Fontos megjegyezni, hogy a fenti haladó direktívák támogatása jelentősen eltérhet a különböző keresőmotorok és robotok között. Ezért általában a legjobb az alapvető direktívákhoz (User-agent, Disallow, Allow, Sitemap) ragaszkodni a feltérképezési viselkedés megbízható szabályozása érdekében.
Hogyan hozzunk létre és implementáljunk egy Robots.txt fájlt
Alapvető Robots.txt fájl létrehozása
- Nyisson meg egy egyszerű szövegszerkesztőt: Használjon egy egyszerű szövegszerkesztőt, mint a Jegyzettömb (Windows), a TextEdit (Mac) vagy egy kódszerkesztőt. Kerülje a szövegszerkesztő programok, például a Microsoft Word használatát, mivel ezek olyan formázást adhatnak hozzá, amely érvénytelenné teszi a fájlt.
- Kezdje a
User-agentdirektívával: Kezdje a megcélozni kívánt felhasználói ügynök(ök) megadásával. Használja aUser-agent: *direktívát a következő szabályok összes robotra való alkalmazásához, vagy adjon meg egy adott robotot, példáulUser-agent: Googlebot. - Adja hozzá a
DisallowésAllowdirektívákat: Külön sorokban adja hozzá a letiltani kívánt útvonalakra vonatkozóDisallowdirektívákat és a kivételekre vonatkozóAllowdirektívákat (ha szükséges). Ne feledje, hogy az útvonalak kis- és nagybetű érzékenyek. - Adja hozzá a
Sitemapdirektívát: Adjon hozzá egy sort, amely megadja az XML oldaltérkép fájljának teljes URL-jét. - Mentse el a fájlt: Mentse el a fájlt pontosan
robots.txt(csupa kisbetűvel) néven. - Töltse fel a gyökérkönyvtárba: Töltse fel a robots.txt fájlt a webhely gyökérkönyvtárába. Ez általában ugyanazon a szinten található, mint az
index.htmlfájl. Ehhez általában egy FTP-kliensre vagy a webhosting szolgáltatója által biztosított fájlkezelőre lesz szüksége.
Hasznos online eszközök és generátorok
Számos online eszköz és generátor segíthet egy alapvető robots.txt fájl létrehozásában. Ezek az eszközök gyakran felhasználóbarát felületet biztosítanak, ahol kiválaszthatja a gyakori direktívákat, és létrehozhatja a fájlt anélkül, hogy manuálisan kellene beírnia a szintaxist. Azonban mindig ellenőrizze a generált fájlt, hogy az megfelel-e az Ön egyedi igényeinek.
Bemutatkozik a Robots.txt elemző
Haladóbb felhasználási esetekben a fejlesztőknek programozottan kellhet elemezniük vagy érvényesíteniük a robots.txt fájlokat. Itt jönnek képbe a dedikált elemzők. Például létrehozhat egy olyan eszközt, amely automatikusan ellenőrzi a gyakori robots.txt hibákat nagyszámú webhelyen.
Ismerje meg a robotstxt.js-t
Bemutatkozik a robotstxt.js, egy könnyű és hatékony JavaScript-alapú robots.txt elemző: https://github.com/playfulsparkle/robotstxt.js (új ablakban nyílik meg).
Főbb jellemzők és előnyök:
- Könnyű és hatékony: Minimális terhelésre és gyors feldolgozásra tervezve.
- JavaScript-alapú: Zökkenőmentesen integrálható webfejlesztői környezetekbe és Node.js alkalmazásokba.
Hasznos olyan feladatokhoz, mint:
- Programozottan ellenőrizni, hogy egy adott URL tiltott-e egy adott felhasználói ügynök számára: Ez lehetővé teszi egyedi logika létrehozását a robots.txt szabályok alapján.
- Egyedi robots.txt elemző eszközök létrehozása: A robotstxt.js segítségével olyan eszközöket hozhat létre, amelyek automatikusan érvényesítik és azonosítják a potenciális problémákat a robots.txt fájlokban.
- A robots.txt elemzés integrálása más JavaScript alkalmazásokba: Például beépítheti a robots.txt ismeretét saját weboldal-adatgyűjtő vagy feltérképező eszközeibe.
Ahhoz, hogy valóban megértsük egy webhely keresőmotorok számára való elérhetőségét, a robots.txt elemző (új ablakban nyílik meg) létfontosságú szerepet játszik. Például a Playful Sparkle SEO Audit (új ablakban nyílik meg), egy könnyű SEO auditáló eszköz, amely böngésző bővítményként érhető el, aktívan beépíti ezt a technológiát.
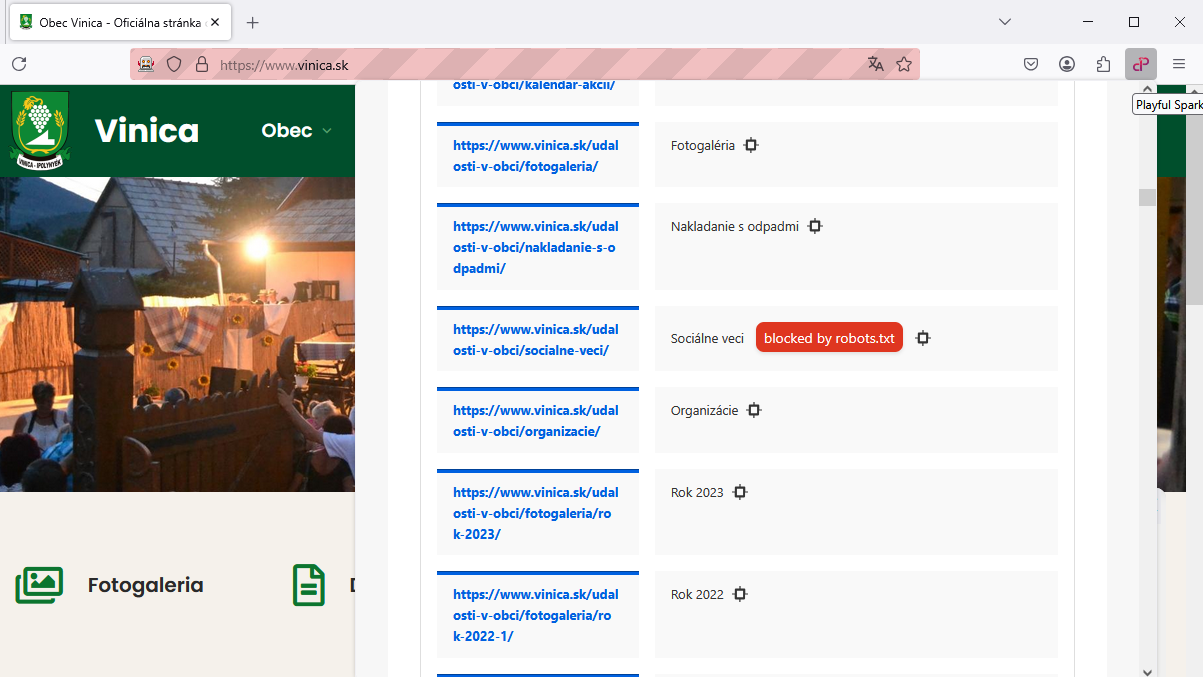
Egy webhely robots.txt fájljának elemzésével a bővítmény meg tudja állapítani, hogy az éppen megtekintett weboldal URL-je szándékosan le van-e tiltva a keresőmotorok feltérképezői elől. Ez értékes, nem tolakodó betekintést nyújt a webhely láthatóságát, felhasználói elkötelezettségét és általános teljesítményét befolyásoló potenciális problémákba a keresési eredmények között.
A Robots Meta Tag-ek és az X-Robots-Tag implementálása
Míg a robots.txt a feltérképezést webhelyszinten szabályozza, az indexelést és a hivatkozások követését oldal- vagy egyedi erőforrás szinten is szabályozhatja a robots meta tag-ek és az X-Robots-Tag segítségével.
- Robots Meta Tag-ek: (
<meta name="robots" content="...">): Ezek egy HTML-oldal<head>részében helyezkednek el, és utasításokat adnak a keresőmotorok feltérképezőinek az adott oldal kezelésére vonatkozóan. A tartalom attribútum gyakori értékei közé tartoznak:noindex:Megakadályozza az oldal indexelését.nofollow:Megakadályozza, hogy a keresőmotorok kövessenek bármilyen hivatkozást az oldalon.noindex, nofollow:A két direktíva kombinációja.index, follow:Az alapértelmezett viselkedés, amely explicit módon engedélyezi az indexelést és a követést.none:A noindex, nofollow-nak megfelelő.all:Az index, follow-nak megfelelő.
<head> <meta name="robots" content="noindex"> </head> X-Robots-Tag: Ez egy HTTP-fejléc, amely hasonlóan szabályozza az indexelést és a követést nem HTML-alapú erőforrások, például PDF-fájlok, képek és videók esetében. HTML-oldalakhoz is használható.
Példa (a szerver konfigurációs fájljában, pl. .htaccess Apache esetén):<FilesMatch "\.(pdf|jpg|jpeg|png)$"> Header set X-Robots-Tag "noindex" </FilesMatch>
A Robots.txt, a Robots Meta Tag-ek és az X-Robots-Tag közötti különbségek
- Robots.txt: Szabályozza, hogy a feltérképezők a webhely mely részeihez férhetnek hozzá. Ez egy webhelyszintű direktíva.
- Robots Meta Tag-ek: Szabályozzák, hogy az egyes HTML-oldalakat hogyan kell indexelni, és hogy a rajtuk lévő hivatkozásokat követni kell-e. Ez egy oldalszintű direktíva.
X-Robots-Tag: Hasonló szabályozást biztosít, mint a robots meta tag-ek, de nem HTML-alapú erőforrásokhoz is használható, és a HTTP-fejléc szintjén van implementálva.
Ezek a módszerek együttesen működnek, hogy részletes szabályozást biztosítsanak a keresőmotorok webhelye tartalmával való interakciójában.
A Robots.txt legjobb gyakorlatai
- Tartsa egyszerűen: Kerülje a felesleges bonyolultságot a robots.txt fájlban. Használjon világos és tömör direktívákat.
- Tesztelje alaposan: Használjon olyan eszközöket, mint a Google Search Console robots.txt tesztelője, hogy megbizonyosodjon arról, hogy a fájl helyesen van formázva és eléri a kívánt célokat.
- Legyen konkrét: Célozza meg a szabályozni kívánt feltérképezőket és tartalmat. Kerülje az olyan széles körű tiltásokat, amelyek véletlenül fontos oldalakat blokkolhatnak.
- Ne használja a Robots.txt-t érzékeny információk elrejtésére: Mivel nyilvánosan hozzáférhető, nem biztonsági intézkedés. Használjon megfelelő hitelesítési és engedélyezési módszereket az érzékeny adatokhoz.
- Hivatkozzon az oldaltérképére: Könnyítse meg a keresőmotorok számára az összes fontos oldal megtalálását a
Sitemapdirektíva hozzáadásával. - Rendszeresen ellenőrizze: Ahogy webhelye fejlődik, rendszeresen ellenőrizze és frissítse a robots.txt fájlt, hogy az továbbra is megfeleljen SEO stratégiájának.
- Helyezze a gyökérkönyvtárba: Bizonyosodjon meg arról, hogy a robots.txt fájl a domain gyökérkönyvtárában található.
- Használjon megjegyzéseket: Adjon hozzá megjegyzéseket a
#szimbólummal az egyes direktívák céljának magyarázatához, különösen összetettebb fájlok esetén.
Gyakori hibák, amelyeket el kell kerülni a Robots.txt használatakor
- Fontos tartalom véletlen blokkolása: Ez kritikus hiba, amely megakadályozhatja, hogy a keresőmotorok indexeljék értékes oldalait, ami jelentős organikus forgalomcsökkenéshez vezethet. Kétszer is ellenőrizze a
Disallowszabályait. - Helytelen szintaxis használata: A szintaxisban még egy apró elírás is okozhatja, hogy a keresőmotorok félreértelmezik vagy figyelmen kívül hagyják a robots.txt fájlt. Fordítson nagy figyelmet a helyesírásra és a formázásra.
- A változtatások tesztelésének elmulasztása: Egy új vagy módosított robots.txt fájl tesztelés nélküli élesítése nem kívánt következményekhez vezethet. A változtatások élesítése előtt mindig használjon tesztelő eszközöket.
- A teljes titoktartás feltételezése: Ne feledje, hogy a robots.txt egy nyilvános fájl. Ne támaszkodjon rá bizalmas információk elrejtésére.
- Az összes robot blokkolása: Ha véletlenül a
Disallow: /direktívát használja az összes felhasználói ügynökre, az megakadályozza, hogy az összes keresőmotor feltérképezze a teljes webhelyét. - Az oldaltérkép direktíva elfelejtése: A
Sitemapdirektíva kihagyása megnehezítheti a keresőmotorok számára az összes fontos oldal felfedezését.
A Robots.txt figyelmeztetéseinek és problémáinak azonosítása és javítása
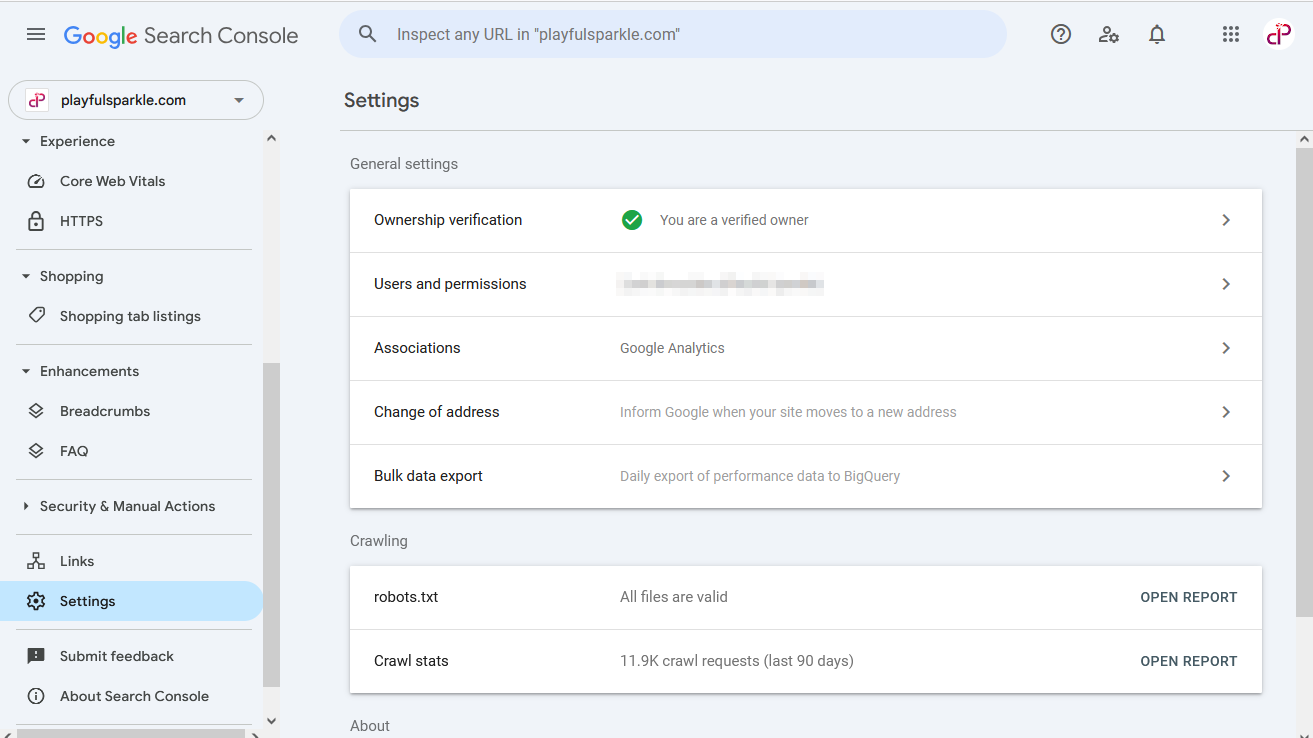
A Google Search Console felbecsülhetetlen értékű eszköz a robots.txt fájllal kapcsolatos problémák azonosításához és javításához.
A Robots.txt problémáinak azonosítása
- Lépjen be a Google Search Console fiókjába.
- Válassza ki a webhely tulajdonát.
- Navigáljon a bal oldali menüsorban található Beállítások menüpontra.
- A Feltérképezés szakasz alatt talál egy sort, amely jelzi a robots.txt fájl állapotát (pl. "robots.txt - Minden fájl érvényes").
- Erre a sorra kattintva megnyílik egy jelentés, amely részleteket tartalmaz a domain robots.txt fájljairól, beleértve az azonosított problémákat vagy figyelmeztetéseket. Ez a jelentés lehetővé teszi a robots.txt fájl tartalmának áttekintését, és azt, hogy a Googlebot problémába ütközik-e annak értelmezése során.
Gyakori figyelmeztetések és azok megoldásai
- "robots.txt által blokkolva": Ez a figyelmeztetés a Lefedettség jelentésben (az Index szakaszból érhető el) azt jelzi, hogy néhány oldala le van tiltva a feltérképezés elől. Vizsgálja meg, hogy ez szándékos-e. Ha fontos oldalak vannak blokkolva, tekintse át a Disallow szabályait, és végezze el a szükséges módosításokat.
- Szintaktikai hibák: A Feltérképezés szakaszban található robots.txt jelentés kiemeli a fájlban található szintaktikai hibákat. Javítsa ki ezeket a hibákat, hogy a keresőmotorok megfelelően értsék a direktívákat.
- Helytelen fájlhely: Ha a Google Search Console problémát jelez a robots.txt fájllal kapcsolatban, győződjön meg arról, hogy a fájl neve pontosan robots.txt (kisbetűvel) és a webhely gyökérkönyvtárában található.
Hibaelhárítási lépések
- Gondosan tekintse át a robots.txt jelentésben található
DisallowésAllowszabályait, hogy megbizonyosodjon arról, hogy a kívánt tartalmat és felhasználói ügynököket célozzák meg. - Ellenőrizze, hogy véletlenül nem tiltotta-e le fontos CSS- vagy JavaScript-fájlokat, amelyek megakadályozhatják a Googlebotot az oldalak helyes megjelenítésében (ezt a Lefedettség jelentés vagy más tesztelés jelezheti).
- Ha módosította a robots.txt fájlt, várjon egy kis időt, amíg a keresőmotorok újra feltérképezik és felismerik a frissítéseket. A Google Search Console-ban kérheti bizonyos URL-ek indexelését is, ha korábban le voltak tiltva, és most engedélyezettek.
Blokkolhatom a rosszindulatú robotokat a Robots.txt segítségével?
Igen, potenciálisan blokkolhatja a rosszindulatú robotokat azáltal, hogy a robots.txt fájlban megcélozza azok konkrét User-agent karaktersorozatait. A rosszindulatú technológia fejlődésével különböző rosszindulatú robotokat fejlesztenek ki különböző célokra, beleértve a tartalomgenerálást, a kutatást és az elemzést.
A helyes User-agent azonosításának fontossága
Egy adott rosszindulatú robot blokkolásához ismernie kell annak pontos User-Agent karaktersorozatát. Ezt az információt általában a rosszindulatú robot fejlesztői adják meg. Ezután hozzáadhat egy Disallow direktívát, amely ezt a konkrét felhasználói ügynököt célozza meg.
Példa: Ha egy hipotetikus "Pelda-RosszindulatuBot" felhasználói ügynökkel rendelkező rosszindulatú robotot szeretne blokkolni:
User-agent: Pelda-RosszindulatuBot
Disallow: /Ez megakadályozná, hogy a "Pelda-RosszindulatuBot" hozzáférjen a teljes webhelyéhez.
Szempontok és lehetséges korlátozások
- User-agent hamisítás: Egyes rosszindulatú robotok nem feltétlenül tartják be a bejelentett felhasználói ügynöküket, vagy akár más felhasználói ügynököket (például a Googlebotot) is megpróbálhatnak hamisítani, hogy hozzáférést nyerjenek.
- Fejlődő User-agent-ek: A rosszindulatú robotok felhasználói ügynökének karaktersorozatai idővel változhatnak, ezért előfordulhat, hogy rendszeresen frissítenie kell a robots.txt fájlt a kívánt blokkolás fenntartásához.
- Felfedezési kihívások: Az összes releváns rosszindulatú robot felhasználói ügynökének azonosítása kihívást jelenthet, mivel a rosszindulatú technológia világa folyamatosan fejlődik.
Bár a robots.txt az első védelmi vonal lehet a nem kívánt rosszindulatú robotforgalom ellen, nem biztos, hogy teljesen bolondbiztos megoldás. A robusztusabb szabályozás érdekében más módszereket is meg kell fontolnia, például a sebességkorlátozást vagy az IP-címek szerverszintű blokkolását.
Összefoglaló
A robots.txt fájl alapvető, mégis hatékony eszköz minden SEO szakember vagy weboldal-menedzser eszköztárában. A szintaxisának megértésével, a legjobb gyakorlatok alkalmazásával és a gyakori hibák elkerülésével hatékonyan szabályozhatja, hogy a keresőmotorok feltérképezői hogyan lépnek kapcsolatba a webhelyével, ami jobb SEO teljesítményhez, hatékonyabb feltérképezési költségvetés-kezeléshez és a webhely általános egészségének javulásához vezet. Ne felejtse el rendszeresen tesztelni a robots.txt fájlt, és a webhely fejlődésével párhuzamosan módosítani azt a folyamatos optimális teljesítmény biztosítása érdekében.
Ne kockáztassa a robots.txt helytelen konfigurálását és a potenciális SEO károsítását! Maximalizálja feltérképezési hatékonyságát és SEO potenciálját
azáltal, hogy szakértőink implementálják és optimalizálják robots.txt fájlját. Lépjen kapcsolatba velünk még ma, hogy kiaknázza webhelye keresőmotorokban való láthatóságának teljes potenciálját.
Kérdések
A webhely gyökérkönyvtárában kell elhelyezkednie (pl. https://www.sajatdomainom.hu/robots.txt).
Egyszerűen írja be webhelye domainnevét, majd a /robots.txt-t a webböngésző címsorába (pl. sajatdomainom.hu/robots.txt). Ha létezik fájl, látni fogja a tartalmát.
Létrehozhat egy robots.txt nevű egyszerű szöveges fájlt egy szövegszerkesztő segítségével, majd feltöltheti a webhely gyökérkönyvtárába FTP-n vagy a hosting szolgáltatója által biztosított fájlkezelőn keresztül.
Kövesse ugyanazt a módszert, mint a sajátjánál: írja be a webhely domainjét, majd a /robots.txt-t a böngészőjébe.
Nem, a robots.txt egy irányelv- vagy kérésrendszer, nem pedig jogi követelmény. Bár a legtöbb jó hírű keresőmotor és robot tiszteletben tartja ezeket a direktívákat, nincs jogi kötelezettségük erre.
Igen, a robots.txt továbbra is kulcsfontosságú eszköz a feltérképező robotok hozzáférésének szabályozásához és a webhely keresőmotorokra való optimalizálásához.
robots.txt:A webhelyszintű feltérképező hozzáférést szabályozza.meta robots tag:Az egyes HTML-oldalak indexelését és a hivatkozások követését szabályozza.X-Robots-Tag:A nem HTML-alapú erőforrások indexelését és a hivatkozások követését szabályozza, és HTML-oldalakhoz is használható HTTP-fejléceken keresztül.
El kell érnie a robots.txt fájlt a webszerverén. Ezt általában egy FTP-kliensen vagy a webhosting szolgáltatója által biztosított fájlkezelőn keresztül teheti meg. Töltse le a fájlt, szerkessze egy szövegszerkesztőben, majd töltse fel újra a gyökérkönyvtárba, felülírva a meglévő fájlt.
Erőforrások
- Google robots.txt specifications (új ablakban nyílik meg)
- Yandex robots.txt specifications (új ablakban nyílik meg)
- Sean Conner:
An Extended Standard for Robot Exclusion
(új ablakban nyílik meg) - Martijn Koster:
A Method for Web Robots Control
(új ablakban nyílik meg) - Martijn Koster:
A Standard for Robot Exclusion
(új ablakban nyílik meg) - RFC 7231 (új ablakban nyílik meg),
2616(új ablakban nyílik meg) - RFC 7230 (új ablakban nyílik meg),
2616(új ablakban nyílik meg) - RFC 5322 (új ablakban nyílik meg),
2822(új ablakban nyílik meg),822(új ablakban nyílik meg) - RFC 3986 (új ablakban nyílik meg),
1808(új ablakban nyílik meg) - RFC 1945 (új ablakban nyílik meg)
- RFC 1738 (új ablakban nyílik meg)
- RFC 952 (új ablakban nyílik meg)

Szerző Oroszlány Zsolt
A Playful Sparkle kreatív ügynökség tulajdonosa több mint 20 évnyi szakértelmet hoz a grafikai tervezés és programozás területén. Innovatív projektek vezetésével foglalkozik, szabadidejében edzés, filmnézés és új CSS funkciók kipróbálása közben tölti az idejét. Zsolt elkötelezettsége a munkája és hobbijai iránt a siker hajtóereje a kreatív iparágban.
Vágjunk bele közösen, és valósítsuk meg elképzeléseit – együtt!
Kérek egy ingyenes árajánlatotKapcsolódó cikkek

Mi az keresőoptimalizálás? (SEO)
Tapasztalt marketing szakemberekként, akik a mai gyorsan változó digitális környezetben dolgoznak, tudjátok, hogy a keresőmotor-optimalizálás (SEO) kiemelkedő jelentőségű. Az SEO elsajátítása nem csupán választási lehetőség, hanem stratégiai kényszer a fenntartható növekedés és a marketing befektetések optimalizálása érdekében. További információ az Mi az keresőoptimalizálás? (SEO)

Győződjön meg róla, hogy az SEO stratégiája készen áll 2025-re
Napjaink digitális korában elengedhetetlen az erős online jelenlét fenntartása, ezért kulcsfontosságú, hogy SEO stratégiái dinamikusak és előremutatóak legyenek. A 2025-ös év közeledtével itt a tökéletes alkalom SEO megközelítésének felülvizsgálatára és finomítására. További információ az Győződjön meg róla, hogy az SEO stratégiája készen áll 2025-re

Átfogó útmutató a helyi keresőoptimalizáláshoz
A helyi SEO (Search Engine Optimization) az online jelenlét optimalizálásának folyamata, amelynek célja, hogy több üzletet vonzzon a releváns helyi keresésekből. További információ az Átfogó útmutató a helyi keresőoptimalizáláshoz