Robots.txt: Čo to je a ako ho správne nastaviť

Pre efektívnu správu webovej stránky a optimalizáciu pre vyhľadávače (SEO) je nevyhnutné riadiť, ako prehľadávače vyhľadávacích nástrojov navigujú vašu stránku. Toto je úloha súboru robots.txt, súboru, ktorý funguje ako digitálny vrátnik a smeruje týchto robotov do prístupných a obmedzených oblastí. Táto príručka ponúka dôkladné preskúmanie súboru robots.txt, pokrýva jeho syntax, osvedčené postupy a stratégie na maximalizáciu výhod SEO.
Stručne
Súbor robots.txt riadi, ako prehľadávače vyhľadávacích nástrojov (ako Googlebot) pristupujú k vašej webovej stránke, čím zabraňuje indexovaniu duplicitného obsahu, šetrí rozpočet na prehľadávanie a udržuje súkromné oblasti skryté. Správna konfigurácia súboru robots.txt pomocou direktív ako Disallow, Allow a Sitemap je rozhodujúca pre dobré SEO a zdravie webovej stránky. Používajte ho múdro na optimalizáciu vašej stránky pre prehľadávače vyhľadávacích nástrojov a zlepšenie indexovania.
Preskúmame základné koncepty, syntax direktív, pokročilé aspekty, kroky implementácie, osvedčené postupy, bežné chyby, riešenie problémov a často kladené otázky týkajúce sa súboru robots.txt.
Pochopenie základov súboru Robots.txt
Ako funguje súbor Robots.txt
Keď prehľadávač vyhľadávacieho nástroja, ako napríklad Googlebot alebo Bingbot, navštívi vašu webovú stránku, prvou vecou, ktorú zvyčajne hľadá, je súbor robots.txt. Ak ho nájde, prečíta si pokyny predtým, ako začne prehľadávať ďalšie časti vašej stránky. Tieto pokyny, známe ako direktívy, hovoria prehľadávaču, ku ktorým URL adresám má povolený alebo zakázaný prístup. Ak sa nenájde žiadny súbor robots.txt, prehľadávač zvyčajne predpokladá, že môže prehľadávať všetky časti webovej stránky.
Je dôležité pochopiť, že súbor robots.txt je súborom smerníc, nie neomylným bezpečnostným opatrením. Hoci väčšina renomovaných prehľadávačov vyhľadávacích nástrojov bude tieto direktívy rešpektovať, škodlivé roboty alebo iné typy webových scraperov ich môžu ignorovať. Preto by ste sa nikdy nemali spoliehať na súbor robots.txt pri ochrane citlivých informácií.
Výhody používania súboru Robots.txt pre SEO
- Zabránenie indexovaniu duplicitného obsahu: Vyhľadávacie nástroje niekedy môžu indexovať viacero verzií toho istého obsahu, ako napríklad stránky vhodné na tlač alebo stránky s rôznymi parametrami URL. Zakázaním prístupu k týmto duplicitným verziám v súbore robots.txt môžete pomôcť vyhľadávacím nástrojom zamerať sa na indexovanie vášho primárneho, vysokokvalitného obsahu.
- Šetrenie rozpočtu na prehľadávanie: Vyhľadávacie nástroje prideľujú každej webovej stránke určitý „rozpočet na prehľadávanie“, ktorý predstavuje počet stránok, ktoré prehľadajú v danom časovom rámci. Blokovaním prístupu k menej dôležitým stránkam (ako sú interné výsledky vyhľadávania alebo testovacie prostredia) zabezpečíte, že prehľadávače vyhľadávacích nástrojov strávia svoj drahocenný čas prehľadávaním a indexovaním vášho najdôležitejšieho obsahu určeného pre používateľov.
- Kontrola prístupu k špecifickým oblastiam: Môžete mať časti vašej webovej stránky, ktoré nie sú určené na verejný prístup alebo indexovanie, ako napríklad administratívne panely, interné nástroje alebo vývojové prostredia. Súbor robots.txt vám umožňuje zabrániť prehľadávačom vyhľadávacích nástrojov v prístupe k týmto oblastiam, čím ich drží mimo výsledkov vyhľadávania.
- Správa zaťaženia servera: Ak vaša webová stránka zaznamenáva vysokú návštevnosť alebo má obmedzené serverové zdroje, môžete použiť súbor robots.txt na odradenie agresívneho prehľadávania niektorými robotmi, čím pomôžete predchádzať preťaženiu servera.
Základný formát súboru Robots.txt
Súbor robots.txt je obyčajný textový súbor s presným názvom „robots.txt“ a musí sa nachádzať v koreňovom adresári vašej webovej stránky (napr. https://www.vasadomena.sk/robots.txt). Každá direktíva v súbore sa nachádza na samostatnom riadku a riadi sa špecifickou syntaxou. Základná štruktúra zahŕňa špecifikáciu User-agent (názov robota, na ktorý sa direktíva vzťahuje) nasledovanú jednou alebo viacerými direktívami, ako napríklad Disallow alebo Allow.
Základné direktívy súboru Robots.txt: Syntax a príklady
Tu sú základné direktívy, ktoré budete bežne používať vo vašom súbore robots.txt:
User-agent: Táto direktíva identifikuje špecifický webový prehľadávač alebo robota, na ktorý sa vzťahujú nasledujúce pravidlá. Môžete cielene zamerať konkrétnych robotov alebo použiť hviezdičku (*) na zacielenie všetkých robotov.- Príklad: Zacielenie na Googlebot:
User-agent: Googlebot - Príklad: Zacielenie na Bingbot:
User-agent: Bingbot - Príklad: Zacielenie na všetky roboty:
User-agent: *
- Príklad: Zacielenie na Googlebot:
Disallow: Táto direktíva hovorí špecifikovaným používateľským agentom, aby nepristupovali k určenej ceste.- Príklad: Blokovanie všetkých robotov z priečinka /admin/:
Toto zabráni všetkým prehľadávačom vyhľadávacích nástrojov v prístupe k akýmkoľvek súborom alebo podpriečinkom v rámci adresáraUser-agent: * Disallow: /admin//admin/.
- Príklad: Blokovanie všetkých robotov z priečinka /admin/:
Allow: Táto direktíva umožňuje špecifikovaným používateľským agentom pristupovať k určitej ceste, aj keď sa nachádza v rámci adresára, ktorý je inak zakázaný. Upozorňujeme, že nie všetky vyhľadávacie nástroje plne podporujú direktívuAllow, preto ju používajte opatrne.- Príklad: Povolenie prístupu Googlebotu k špecifickému súboru v zakázanom priečinku:
V tomto prípade sú všetky súbory v priečinkuUser-agent: Googlebot Disallow: /obrazky/ Allow: /obrazky/specificky-obrazok.jpg/obrazky/pre Googlebot všeobecne zakázané, s výnimkou súboru/obrazky/specificky-obrazok.jpg.
- Príklad: Povolenie prístupu Googlebotu k špecifickému súboru v zakázanom priečinku:
Sitemap: Táto direktíva špecifikuje umiestnenie vašej XML sitemap(y), ktorá pomáha vyhľadávacím nástrojom objavovať a prehľadávať všetky dôležité stránky na vašej webovej stránke. V súbore robots.txt môžete mať viacero direktívSitemap.- Príklad: Prepojenie na vašu XML sitemapu:
Sitemap: https://www.vasadomena.sk/sitemap.xml - Ak máte viacero sitemap:
Sitemap: https://www.vasadomena.sk/sitemap_index.xml Sitemap: https://www.vasadomena.sk/sitemap_products.xml
- Príklad: Prepojenie na vašu XML sitemapu:
Ostatné direktívy
Host: Táto direktíva sa používala na špecifikáciu preferovanej domény pre vašu webovú stránku, najmä pre staršie vyhľadávacie nástroje. Moderné vyhľadávacie nástroje to zvyčajne riešia prostredníctvom kanonických značiek a iných metód, takžeHostsa v súčasnosti používa menej často.- Príklad:
Host: www.vasadomena.sk
- Príklad:
Crawl-delay: Táto direktíva navrhuje oneskorenie v sekundách medzi požiadavkami na prehľadávanie od konkrétneho robota. Môže to byť užitočné na zabránenie preťaženiu vášho servera agresívnymi prehľadávačmi. Avšak nie všetky vyhľadávacie nástroje túto direktívu rešpektujú a spoločnosť Google odporúča namiesto toho používať nastavenia rýchlosti prehľadávania v službe Google Search Console.- Príklad:
User-agent: * Crawl-delay: 5
- Príklad:
Clean-param: Táto direktíva hovorí vyhľadávacím nástrojom, aby ignorovali špecifické parametre URL, aby sa zabránilo indexovaniu duplicitného obsahu spôsobeného týmito parametrami (napr. sledovacie ID). Spoločnosť Google túto direktívu zrušila a vo všeobecnosti je lepšie riešiť spracovanie parametrov v službe Google Search Console.- Príklad:
Clean-param: sessionid /produkty/index.php
- Príklad:
Pokročilé direktívy a aspekty súboru Robots.txt
Hoci základné direktívy pokrývajú väčšinu bežných prípadov použitia, existujú niektoré menej často používané direktívy a aspekty:
Request-rate: Táto direktíva navrhuje maximálny počet požiadaviek, ktoré by mal prehľadávač vykonať za minútu. Nie je široko podporovaná hlavnými vyhľadávacími nástrojmi.Cache-delay: Táto direktíva navrhuje, ako dlho by mali prehľadávače čakať pred opätovným prehľadaním stránky. Nie je bežne podporovaná.Visit-time: Táto direktíva navrhuje špecifické denné časy, kedy by mali prehľadávače navštíviť webovú stránku. Nie je široko podporovaná.Robot-version: Táto direktíva špecifikuje verziu používaného protokolu vylúčenia robotov. V praxi sa používa zriedka.
Je dôležité pamätať na to, že podpora týchto pokročilých direktív sa môže výrazne líšiť medzi rôznymi vyhľadávacími nástrojmi a robotmi. Preto je vo všeobecnosti najlepšie držať sa základných direktív (User-agent, Disallow, Allow, Sitemap) pre spoľahlivú kontrolu nad správaním prehľadávania.
Ako vytvoriť a implementovať súbor Robots.txt
Vytvorenie základného súboru Robots.txt
- Otvorte jednoduchý textový editor: Použite jednoduchý textový editor, ako napríklad Poznámkový blok (Windows), TextEdit (Mac) alebo editor kódu. Vyhnite sa používaniu textových procesorov, ako je Microsoft Word, pretože môžu pridať formátovanie, ktoré spôsobí, že súbor bude neplatný.
- Začnite s
User-agent: Začnite špecifikovaním používateľských agentov, na ktoré chcete zacieliť. PoužiteUser-agent: *na použitie nasledujúcich pravidiel na všetky roboty, alebo špecifikujte konkrétneho robota, ako napríkladUser-agent: Googlebot. - Pridajte direktívy
DisallowaAllow: Na samostatné riadky pridajte direktívyDisallowpre cesty, ktoré chcete zablokovať, a direktívyAllow(ak je to potrebné) pre výnimky. Pamätajte, že cesty rozlišujú veľké a malé písmená. - Zahrňte direktívu
Sitemap: Pridajte riadok špecifikujúci úplnú URL adresu vášho súboru XML sitemapy. - Uložte súbor: Súbor uložte presne pod názvom
robots.txt(všetky malé písmená). - Nahrajte do koreňového adresára: Nahrajte súbor robots.txt do koreňového adresára vašej webovej stránky. Zvyčajne je to rovnaká úroveň ako váš súbor
index.html. Na to budete zvyčajne potrebovať FTP klienta alebo správcu súborov poskytnutého vaším poskytovateľom webhostingu.
Užitočné online nástroje a generátory
Niekoľko online nástrojov a generátorov vám môže pomôcť vytvoriť základný súbor robots.txt. Tieto nástroje často poskytujú používateľsky prívetivé rozhranie, kde si môžete vybrať bežné direktívy a vygenerovať súbor bez potreby manuálneho zadávania syntaxe. Vždy však skontrolujte vygenerovaný súbor, aby ste sa uistili, že vyhovuje vašim špecifickým potrebám.
Predstavujeme analyzátory súboru Robots.txt
Pre pokročilejšie prípady použitia môžu vývojári potrebovať programovo analyzovať alebo validovať súbory robots.txt. Tu prichádzajú na rad špecializované analyzátory. Napríklad, možno budete chcieť vytvoriť nástroj, ktorý automaticky kontroluje bežné chyby súboru robots.txt na veľkom počte webových stránok.
Zoznámte sa s robotstxt.js
Predstavujeme robotstxt.js, odľahčený a efektívny analyzátor súboru robots.txt založený na jazyku JavaScript: https://github.com/playfulsparkle/robotstxt.js (otvorí sa v novom okne).
Kľúčové vlastnosti a výhody:
- Ľahký a efektívny: Navrhnutý pre minimálnu réžiu a rýchle spracovanie.
- Založený na jazyku JavaScript: Bezproblémovo sa integruje do vývojových prostredí webových aplikácií a aplikácií Node.js.
Užitočný pre úlohy ako:
- Programové overenie, či je konkrétna URL adresa zakázaná pre daného používateľského agenta: To vám umožní vytvárať vlastnú logiku na základe pravidiel súboru robots.txt.
- Vytváranie vlastných nástrojov na analýzu súboru robots.txt: Môžete použiť robotstxt.js na vytváranie nástrojov, ktoré automaticky validujú a identifikujú potenciálne problémy v súboroch robots.txt.
- Integrácia analýzy súboru robots.txt do iných aplikácií JavaScript: Napríklad, možno budete chcieť zahrnúť povedomie o súbore robots.txt do vašich vlastných nástrojov na web scraping alebo prehľadávanie.
Na skutočné pochopenie prístupnosti webovej stránky pre vyhľadávacie nástroje zohráva kľúčovú úlohu analyzátor súboru robots.txt (otvorí sa v novom okne). Napríklad Playful Sparkle SEO Audit (otvorí sa v novom okne), odľahčený nástroj na SEO audit dostupný ako rozšírenie prehliadača, aktívne využíva túto technológiu.
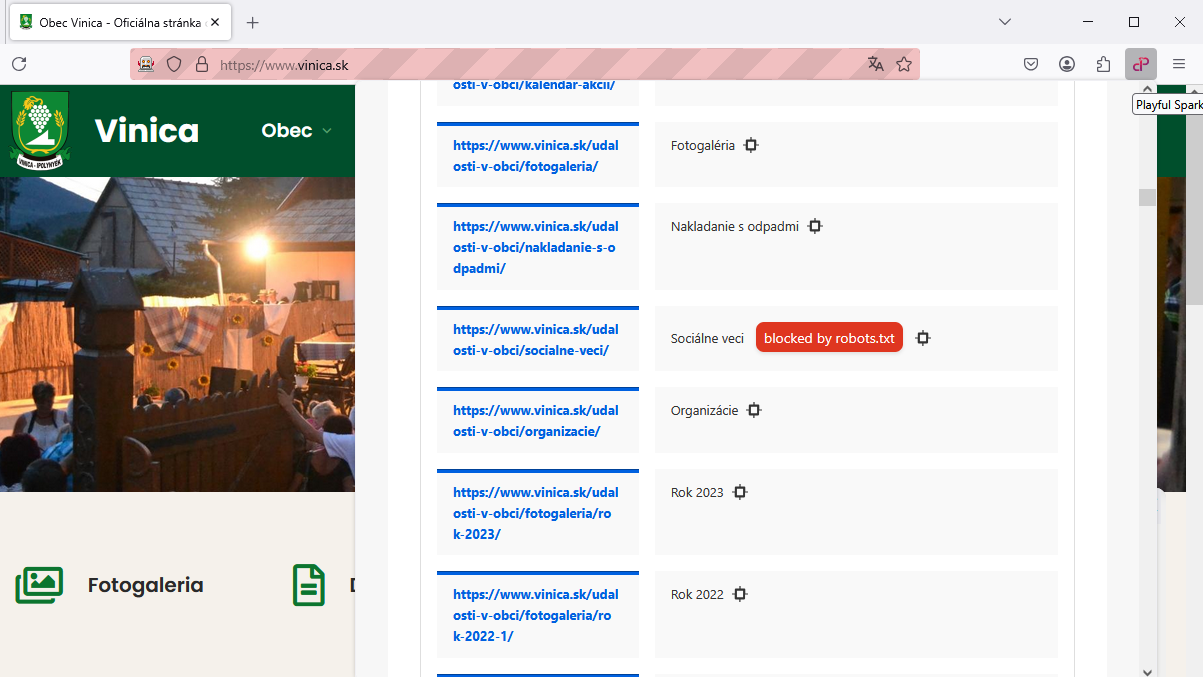
Analýzou súboru robots.txt webovej stránky môže rozšírenie určiť, či je URL adresa aktuálne zobrazenej webovej stránky zámerne blokovaná pre prehľadávače vyhľadávacích nástrojov. To poskytuje cenné, nenápadné informácie o potenciálnych problémoch ovplyvňujúcich viditeľnosť webovej stránky, zapojenie používateľov a celkovú výkonnosť vo výsledkoch vyhľadávania.
Implementácia meta značiek robots a X-Robots-Tag
Zatiaľ čo súbor robots.txt riadi prehľadávanie na úrovni webovej stránky, môžete tiež riadiť indexovanie a sledovanie odkazov na úrovni stránky alebo jednotlivých zdrojov pomocou meta značiek robots a X-Robots-Tag.
- Meta značky Robots: (
<meta name="robots" content="...">): Tieto sa umiestňujú do sekcie<head>HTML stránky a poskytujú pokyny prehľadávačom vyhľadávacích nástrojov, ako majú spracovať danú konkrétnu stránku. Bežné hodnoty atribútu content zahŕňajú:noindex:Zabráni indexovaniu stránky.nofollow:Zabráni vyhľadávacím nástrojom sledovať akékoľvek odkazy na stránke.noindex, nofollow:Kombinuje obe direktívy.index, follow:Predvolené správanie, explicitne povoľujúce indexovanie a sledovanie.none:Ekvivalentné k noindex, nofollow.all:Ekvivalentné k index, follow.
<head> <meta name="robots" content="noindex"> </head> X-Robots-Tag: Toto je hlavička HTTP, ktorá poskytuje podobnú kontrolu nad indexovaním a sledovaním pre non-HTML zdroje, ako sú súbory PDF, obrázky a videá. Môže sa použiť aj pre HTML stránky.
Príklad (v konfiguračnom súbore vášho servera, napr. .htaccess pre Apache):<FilesMatch "\.(pdf|jpg|jpeg|png)$"> Header set X-Robots-Tag "noindex" </FilesMatch>
Rozdiely medzi súborom Robots.txt, meta značkami Robots a X-Robots-Tag
- Robots.txt: Riadi, ku ktorým častiam vašej webovej stránky môžu prehľadávače pristupovať. Je to direktíva na úrovni webovej stránky.
- Meta značky Robots: Riadi, ako by sa mali indexovať jednotlivé HTML stránky a či by sa mali sledovať odkazy na nich. Je to direktíva na úrovni stránky.
X-Robots-Tag: Poskytuje podobnú kontrolu ako meta značky robots, ale môže sa použiť pre non-HTML zdroje a implementuje sa na úrovni hlavičky HTTP.
Tieto metódy spolupracujú, aby vám poskytli podrobnú kontrolu nad tým, ako vyhľadávacie nástroje interagujú s obsahom vašej webovej stránky.
Osvedčené postupy pre súbor Robots.txt
- Jednoduchosť: Vyhnite sa zbytočnej zložitosti vo vašom súbore robots.txt. Používajte jasné a stručné direktívy.
- Dôkladné testovanie: Používajte nástroje ako Tester súboru robots.txt v službe Google Search Console, aby ste sa uistili, že váš súbor je správne formátovaný a dosahuje vaše zamýšľané ciele.
- Špecifickosť: Zamerajte sa na prehľadávače a obsah, ktorý chcete kontrolovať. Vyhnite sa rozsiahlym zákazom, ktoré by mohli nechtiac zablokovať dôležité stránky.
- Nepoužívajte súbor Robots.txt na skrytie citlivých informácií: Keďže je verejne prístupný, nie je to bezpečnostné opatrenie. Pre citlivé údaje používajte správne metódy autentifikácie a autorizácie.
- Odkazujte na vašu sitemapu: Uľahčite vyhľadávacím nástrojom nájsť všetky vaše dôležité stránky zahrnutím direktívy
Sitemap. - Pravidelná kontrola: Keď sa vaša webová stránka vyvíja, pravidelne kontrolujte a aktualizujte váš súbor robots.txt, aby ste sa uistili, že stále zodpovedá vašej SEO stratégii.
- Umiestnenie do koreňového adresára: Uistite sa, že súbor robots.txt sa nachádza v koreňovom adresári vašej domény.
- Používanie komentárov: Pridávajte komentáre pomocou symbolu
#na vysvetlenie účelu konkrétnych direktív, najmä v zložitejších súboroch.
Bežné chyby, ktorým sa treba vyhnúť pri používaní súboru Robots.txt
- Nechcené zablokovanie dôležitého obsahu: Toto je kritická chyba, ktorá môže zabrániť vyhľadávacím nástrojom indexovať vaše cenné stránky, čo vedie k výraznému poklesu organickej návštevnosti. Dôkladne skontrolujte vaše pravidlá
Disallow. - Používanie nesprávnej syntaxe: Aj malá preklep v syntaxi môže spôsobiť, že vyhľadávacie nástroje nesprávne interpretujú alebo ignorujú súbor robots.txt. Dávajte pozor na pravopis a formátovanie.
- Netestovanie zmien: Nasadenie nového alebo upraveného súboru robots.txt bez testovania môže viesť k nechceným následkom. Pred zavedením zmien do produkčného prostredia vždy používajte testovacie nástroje.
- Predpoklad úplnej tajnosti: Pamätajte, že súbor robots.txt je verejný súbor. Nespoliehajte sa naň pri skrývaní dôverných informácií.
- Zablokovanie všetkých robotov: Nechcené použitie
Disallow: /pre všetkých používateľských agentov zabráni všetkým vyhľadávacím nástrojom prehľadávať celú vašu webovú stránku. - Zabudnutie na direktívu Sitemap: Nezaradenie direktívy
Sitemapmôže sťažiť vyhľadávacím nástrojom objavenie všetkých vašich dôležitých stránok.
Identifikácia a oprava upozornení a problémov súboru Robots.txt
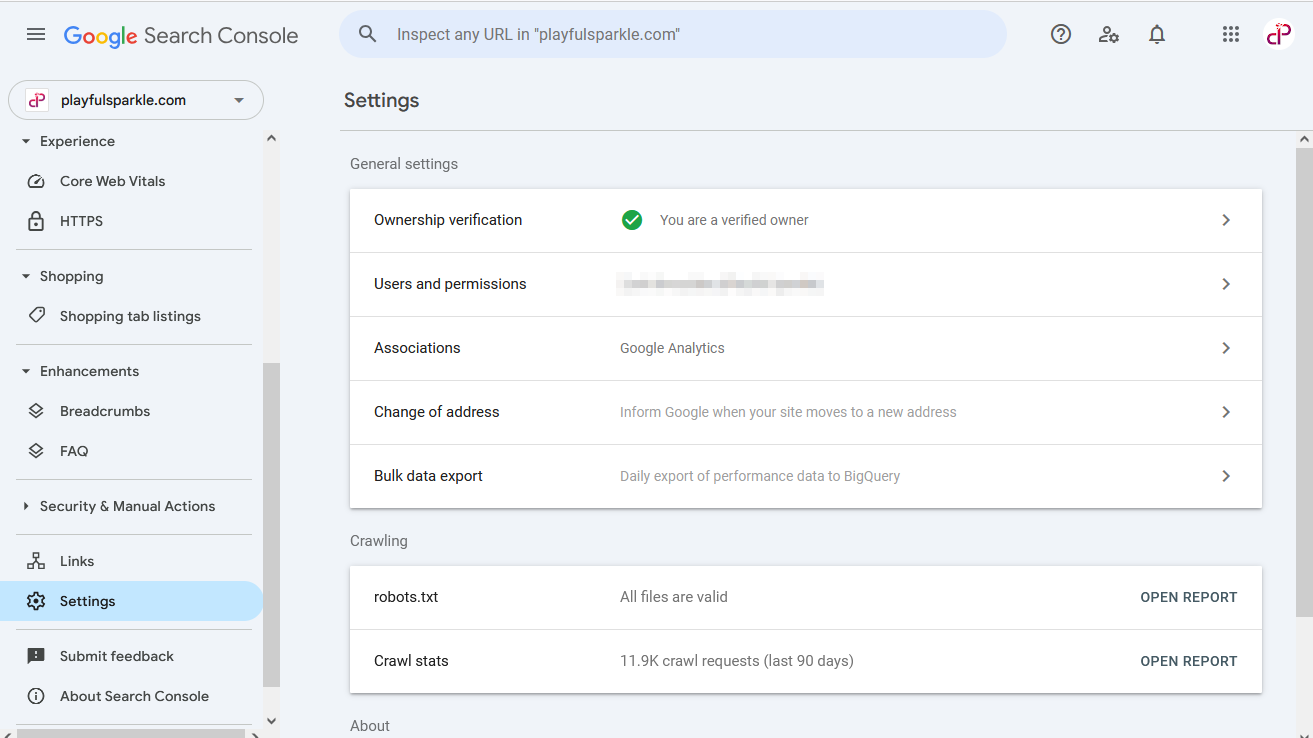
Služba Google Search Console je neoceniteľným nástrojom na identifikáciu a opravu problémov súvisiacich s vaším súborom robots.txt.
Ako identifikovať problémy súboru Robots.txt
- Prejdite na svoj účet Google Search Console.
- Vyberte svoju webovú stránku.
- V ľavom bočnom paneli prejdite na Nastavenia.
- V sekcii Prehľadávanie nájdete riadok označujúci stav vášho súboru robots.txt (napr. „robots.txt – Všetky súbory sú platné“).
- Kliknutím na tento riadok sa otvorí prehľad s podrobnosťami o súboroch robots.txt vašej domény, vrátane akýchkoľvek identifikovaných problémov alebo upozornení. Tento prehľad vám umožňuje skontrolovať obsah vášho súboru robots.txt a zistiť, či Googlebot narazí na nejaké problémy pri jeho interpretácii.
Bežné upozornenia a ich riešenia
- „Blokované súborom robots.txt“: Toto upozornenie v prehľade Pokrytie (prístupné cez sekciu Index) naznačuje, že niektoré z vašich stránok sú blokované pred prehľadávaním. Preskúmajte, či je to zámerné. Ak sú blokované dôležité stránky, skontrolujte svoje pravidlá Disallow a vykonajte potrebné úpravy.
- Chyby syntaxe: Prehľad robots.txt v sekcii Prehľadávanie zvýrazní akékoľvek chyby syntaxe vo vašom súbore. Opravte tieto chyby, aby ste zabezpečili, že vaše direktívy budú správne pochopené vyhľadávacími nástrojmi.
- Nesprávne umiestnenie súboru: Ak služba Google Search Console indikuje problém s vaším súborom robots.txt, uistite sa, že je pomenovaný presne robots.txt (malými písmenami) a umiestnený v koreňovom adresári vašej webovej stránky.
Kroky na riešenie problémov
- Starostlivo skontrolujte svoje pravidlá
DisallowaAllowv prehľade robots.txt, aby ste sa uistili, že cielia na zamýšľaný obsah a používateľských agentov. - Skontrolujte, či ste nechtiac nezablokovali dôležité súbory CSS alebo JavaScript, čo môže zabrániť službe Googlebot správne vykresliť vaše stránky (môže to byť uvedené v prehľade Pokrytie alebo prostredníctvom iných testov).
- Ak ste vykonali zmeny vo vašom súbore robots.txt, nechajte vyhľadávacím nástrojom nejaký čas na opätovné prehľadávanie a rozpoznanie aktualizácií. Môžete tiež požiadať o indexovanie konkrétnych URL adries v službe Google Search Console, ak boli predtým blokované a teraz sú povolené.
Môžem blokovať nežiaduce roboty pomocou súboru Robots.txt?
Áno, potenciálne môžete blokovať nežiaduce roboty zacielením na ich špecifické reťazce User-agent vo vašom súbore robots.txt. S pokrokom v nežiaducej technológii sa vyvíjajú rôzne nežiaduce roboty na rôzne účely, vrátane generovania obsahu, výskumu a analýzy.
Dôležitosť identifikácie správneho používateľského agenta
Ak chcete zablokovať konkrétneho nežiaduceho robota, musíte poznať jeho presný reťazec User-Agent. Tieto informácie zvyčajne poskytujú vývojári nežiaduceho robota. Potom môžete pridať direktívu Disallow, ktorá sa zameriava na tohto konkrétneho používateľského agenta.
Príklad: Ak chcete zablokovať hypotetického nežiaduceho robota s používateľským agentom „NeziaduciRobot-Priklad“:
User-agent: NeziaduciRobot-Priklad
Disallow: /Toto by zabránilo robotovi „NeziaduciRobot-Priklad“ v prístupe k celej vašej webovej stránke.
Aspekty a potenciálne obmedzenia
- Falšovanie používateľského agenta: Niektoré nežiaduce roboty sa nemusia striktne držať svojho deklarovaného používateľského agenta alebo sa dokonca môžu pokúsiť falšovať iných používateľských agentov (ako napríklad Googlebot), aby získali prístup.
- Vyvíjajúce sa používateľské agenty: Reťazce používateľských agentov nežiaducich robotov sa môžu časom meniť, takže možno budete musieť pravidelne aktualizovať váš súbor robots.txt, aby ste si udržali požadované blokovanie.
- Výzvy pri objavovaní: Identifikácia všetkých relevantných používateľských agentov nežiaducich robotov môže byť náročná, pretože prostredie nežiaducej technológie sa neustále vyvíja.
Hoci súbor robots.txt môže byť prvou líniou obrany proti nechcenej návštevnosti nežiaducich robotov, nemusí to byť úplne spoľahlivé riešenie. Pre robustnejšiu kontrolu možno budete musieť preskúmať iné metódy, ako je obmedzenie rýchlosti alebo blokovanie IP adries na úrovni servera.
Záver
Súbor robots.txt je základný, no zároveň výkonný nástroj v arzenáli každého SEO špecialistu alebo správcu webovej stránky. Pochopením jeho syntaxe, implementáciou osvedčených postupov a vyhýbaním sa bežným chybám môžete efektívne riadiť, ako prehľadávače vyhľadávacích nástrojov interagujú s vašou webovou stránkou, čo vedie k lepšej výkonnosti SEO, efektívnej správe rozpočtu na prehľadávanie a zlepšeniu celkového zdravia webovej stránky. Nezabudnite pravidelne testovať váš súbor robots.txt a prispôsobovať ho, ako sa vaša webová stránka vyvíja, aby ste zabezpečili neustálu optimálnu výkonnosť.
Neriskujte nesprávnu konfiguráciu vášho súboru `robots.txt` a potenciálne poškodenie vášho SEO! Maximalizujte efektivitu prehľadávania a SEO potenciál tým, že necháte našich odborníkov implementovať a optimalizovať váš súbor robots.txt. Kontaktujte nás ešte dnes a odomknite plný potenciál viditeľnosti vašej webovej stránky vo vyhľadávacích nástrojoch.
Otázky
Musí sa nachádzať v koreňovom adresári vašej webovej stránky (napr. https://www.vasadomena.sk/robots.txt).
Jednoducho zadajte názov domény vašej webovej stránky, za ktorým nasleduje /robots.txt do panela s adresou vášho webového prehliadača (napr. vasadomena.sk/robots.txt). Ak súbor existuje, zobrazí sa jeho obsah.
Môžete vytvoriť obyčajný textový súbor s názvom robots.txt pomocou textového editora a potom ho nahrať do koreňového adresára vašej webovej stránky prostredníctvom FTP alebo správcu súborov vášho poskytovateľa hostingu.
Postupujte rovnako ako pri kontrole vášho vlastného: zadajte doménu webovej stránky, za ktorou nasleduje /robots.txt vo vašom prehliadači.
Nie, súbor robots.txt je súborom smerníc alebo požiadaviek, nie právnou požiadavkou. Hoci väčšina renomovaných vyhľadávacích nástrojov a robotov bude tieto direktívy rešpektovať, neexistuje žiadna právna povinnosť, aby tak urobili.
Áno, súbor robots.txt zostáva kľúčovým nástrojom na riadenie prístupu prehľadávačov a optimalizáciu vašej webovej stránky pre vyhľadávacie nástroje.
robots.txt:Riadi prístup prehľadávačov na úrovni celej webovej stránky.meta robots tag:Riadi indexovanie a sledovanie odkazov pre jednotlivé HTML stránky.X-Robots-Tag:Riadi indexovanie a sledovanie odkazov pre non-HTML zdroje a môže sa použiť aj pre HTML stránky prostredníctvom hlavičiek HTTP.
Musíte mať prístup k súboru robots.txt na vašom webovom serveri. Zvyčajne to môžete urobiť prostredníctvom FTP klienta alebo správcu súborov poskytnutého vaším poskytovateľom webhostingu. Stiahnite si súbor, upravte ho v textovom editore a potom ho znova nahrajte do koreňového adresára, čím prepíšete existujúci súbor.
Zdroje
- Google robots.txt specifications (otvorí sa v novom okne)
- Yandex robots.txt specifications (otvorí sa v novom okne)
- Sean Conner:
An Extended Standard for Robot Exclusion
(otvorí sa v novom okne) - Martijn Koster:
A Method for Web Robots Control
(otvorí sa v novom okne) - Martijn Koster:
A Standard for Robot Exclusion
(otvorí sa v novom okne) - RFC 7231 (otvorí sa v novom okne),
2616(otvorí sa v novom okne) - RFC 7230 (otvorí sa v novom okne),
2616(otvorí sa v novom okne) - RFC 5322 (otvorí sa v novom okne),
2822(otvorí sa v novom okne),822(otvorí sa v novom okne) - RFC 3986 (otvorí sa v novom okne),
1808(otvorí sa v novom okne) - RFC 1945 (otvorí sa v novom okne)
- RFC 1738 (otvorí sa v novom okne)
- RFC 952 (otvorí sa v novom okne)

Autor článku Zsolt Oroszlány
Vedúci kreatívnej agentúry Playful Sparkle prináša viac ako 20 rokov skúseností v oblasti grafického dizajnu a programovania. Vedie inovatívne projekty a svoj voľný čas trávi cvičením, pozeraním filmov a experimentovaním s novými funkciami CSS. Zsoltovo oddanie práci a záľubám je hnacou silou jeho úspechu v kreatívnom priemysle.
Spoločne posuňme váš úspech na vyššiu úroveň!
Vyžiadajte si bezplatnú cenovú ponukuSúvisiace články

Čo je optimalizácia pre vyhľadávače? (SEO)
Ako skúsení marketingoví profesionáli pôsobiaci v dnešnom rýchlo sa meniacom digitálnom prostredí dobre viete, aký zásadný význam má optimalizácia pre vyhľadávače (SEO). Prečítajte si viaco Čo je optimalizácia pre vyhľadávače? (SEO)

Uistite sa, že vaša stratégia SEO je pripravená na rok 2025
V dnešnej digitálnej ére je udržiavanie silnej online prítomnosti kľúčové, preto je nevyhnutné, aby boli vaše stratégie SEO dynamické a orientované na budúcnosť. Prečítajte si viaco Uistite sa, že vaša stratégia SEO je pripravená na rok 2025

Komplexný sprievodca lokálnym SEO
Miestne SEO (Search Engine Optimization) je proces optimalizácie vašej online prítomnosti s cieľom prilákať viac zákazníkov z relevantných miestnych vyhľadávaní. Prečítajte si viaco Komplexný sprievodca lokálnym SEO