Robots.txt: The Ultimate Guide to Syntax, Best Practices

For effective website management and Search Engine Optimization (SEO), it's essential to manage how search engine crawlers navigate your site. This is the role of robots.txt, a file that acts as a digital gatekeeper, directing these bots to accessible and restricted areas. This guide offers a thorough exploration of robots.txt, covering its syntax, best practices, and strategies for maximizing SEO benefits.
TL;DR
Robots.txt controls how search engine crawlers (like Googlebot) access your website, preventing indexing of duplicate content, saving crawl budget, and keeping private areas hidden. Properly configuring your robots.txt file using directives like Disallow, Allow, and Sitemap is crucial for good SEO and website health. Use it wisely to optimize your site for search engine crawlers and improve indexing.
We will explore the fundamental concepts, syntax of directives, advanced considerations, implementation steps, best practices, common mistakes, troubleshooting, and frequently asked questions about robots.txt.
Understanding the Fundamentals of Robots.txt
How Robots.txt Works
When a search engine crawler, like Googlebot or Bingbot, visits your website, the first thing it typically looks for is the robots.txt file. If it finds one, it reads the instructions before proceeding to crawl other parts of your site. These instructions, known as directives, tell the crawler which URLs it is allowed or disallowed to access. If no robots.txt file is found, the crawler will usually assume it can crawl all parts of the website.
It's important to understand that robots.txt is a set of guidelines, not a foolproof security measure. While most reputable search engine crawlers will respect these directives, malicious bots or other types of web scrapers might ignore them. Therefore, you should never rely on robots.txt to protect sensitive information.
Benefits of Using Robots.txt for SEO
- Preventing Duplicate Content Indexing: Search engines can sometimes index multiple versions of the same content, such as printer-friendly pages or pages with different URL parameters. By disallowing access to these duplicate versions in your robots.txt file, you can help search engines focus on indexing your primary, high-quality content.
- Conserving Crawl Budget: Search engines allocate a certain "crawl budget" to each website, which represents the number of pages they will crawl within a given timeframe. By blocking access to less important pages (like internal search results or staging environments), you ensure that search engine crawlers spend their valuable time crawling and indexing your most important, user-facing content.
- Controlling Access to Specific Areas: You might have sections of your website that are not intended for public access or indexing, such as administrative dashboards, internal tools, or development environments. robots.txt allows you to prevent search engine crawlers from accessing these areas, keeping them out of search results.
- Managing Server Load: If your website experiences high traffic or has limited server resources, you can use robots.txt to discourage aggressive crawling by certain bots, helping to prevent server overload.
Basic Robots.txt Format
A robots.txt file is a plain text file named exactly "robots.txt" and must be located in the root directory of your website (e.g., https://www.yourdomain.com/robots.txt). Each directive in the file appears on a separate line and follows a specific syntax. The basic structure involves specifying a User-agent (the name of the bot the directive applies to) followed by one or more directives like Disallow or Allow.
Core Robots.txt Directives: Syntax and Examples
Here are the core directives you'll commonly use in your robots.txt file:
User-agent: This directive identifies the specific web crawler or bot that the following rules apply to. You can target specific bots or use an asterisk (*) to target all bots.- Example: To target Googlebot:
User-agent: Googlebot - Example: To target Bingbot:
User-agent: Bingbot - Example: To target all bots:
User-agent: *
- Example: To target Googlebot:
Disallow: This directive tells the specified user agent(s) not to access the specified path.- Example: Blocking all bots from the /admin/ folder:
This prevents all search engine crawlers from accessing any files or subfolders within theUser-agent: * Disallow: /admin//admin/directory.
- Example: Blocking all bots from the /admin/ folder:
Allow: This directive allows the specified user agent(s) to access a specific path, even if it's within a directory that's otherwise disallowed. Note that not all search engines fully support theAllowdirective, so use it with caution.- Example: Allowing Googlebot to access a specific file within a disallowed folder:
In this case, all files in theUser-agent: Googlebot Disallow: /images/ Allow: /images/specific-image.jpg/images/folder are generally disallowed for Googlebot, except for/images/specific-image.jpg.
- Example: Allowing Googlebot to access a specific file within a disallowed folder:
Sitemap: This directive specifies the location of your XML sitemap(s), which helps search engines discover and crawl all the important pages on your website. You can have multipleSitemapdirectives in your robots.txt file.- Example: Linking to your XML sitemap:
Sitemap: https://www.yourdomain.com/sitemap.xml - If you have multiple sitemaps:
Sitemap: https://www.yourdomain.com/sitemap_index.xml Sitemap: https://www.yourdomain.com/sitemap_products.xml
- Example: Linking to your XML sitemap:
Other Directives
Host: This directive was used to specify the preferred domain for your website, particularly for older search engines. Modern search engines generally handle this through canonical tags and other methods, soHostis less commonly used now.- Example:
Host: www.yourdomain.com
- Example:
Crawl-delay: This directive suggests a delay in seconds between crawl requests made by a specific bot. This can be useful to prevent your server from being overwhelmed by aggressive crawlers. However, not all search engines honor this directive, and Google recommends using crawl rate settings within Google Search Console instead.- Example:
User-agent: * Crawl-delay: 5
- Example:
Clean-param: This directive tells search engines to ignore specific URL parameters to prevent indexing of duplicate content caused by these parameters (e.g., tracking IDs). Google has deprecated this directive, and it's generally better to handle parameter handling within Google Search Console.- Example:
Clean-param: sessionid /products/index.php
- Example:
Advanced Robots.txt Directives and Considerations
While the core directives cover most common use cases, there are some less frequently used directives and considerations:
Request-rate: This directive suggests the maximum number of requests a crawler should make per minute. It's not widely supported by major search engines.Cache-delay: This directive suggests how long crawlers should wait before re-crawling a page. It's not commonly supported.Visit-time: This directive suggests specific times of day when crawlers should visit the website. It's not widely supported.Robot-version: This directive specifies the version of the Robots Exclusion Protocol being used. It's rarely used in practice.
It's crucial to remember that support for these advanced directives can vary significantly between different search engines and bots. Therefore, it's generally best to stick to the core directives (User-agent, Disallow, Allow, Sitemap) for reliable control over crawling behavior.
How to Create and Implement a Robots.txt File
Creating a Basic Robots.txt File
- Open a plain text editor: Use a simple text editor like Notepad (Windows), TextEdit (Mac), or a code editor. Avoid using word processors like Microsoft Word, as they can add formatting that will make the file invalid.
- Start with
User-agent: Begin by specifying the user agent(s) you want to target. UseUser-agent: *to apply the following rules to all bots, or specify a particular bot likeUser-agent: Googlebot. - Add
DisallowandAllowdirectives: On separate lines, add theDisallowdirectives for the paths you want to block andAllowdirectives (if needed) for exceptions. Remember that paths are case-sensitive. - Include the
Sitemapdirective: Add a line specifying the full URL of your XML sitemap file. - Save the file: Save the file as exactly
robots.txt(all lowercase). - Upload to the root directory: Upload the robots.txt file to the root directory of your website. This is usually the same level as your
index.htmlfile. You'll typically need to use an FTP client or a file manager provided by your web hosting provider to do this.
Helpful Online Tools and Generators
Several online tools and generators can help you create a basic robots.txt file. These tools often provide a user-friendly interface where you can select common directives and generate the file without needing to manually type the syntax. However, always review the generated file to ensure it meets your specific needs.
Introducing Robots.txt Parsers
For more advanced use cases, developers might need to programmatically analyze or validate robots.txt files. This is where dedicated parsers come in handy. For example, you might want to build a tool that automatically checks for common robots.txt errors across a large number of websites.
Meet robotstxt.js
Introducing robotstxt.js, a lightweight and efficient JavaScript-based robots.txt parser: https://github.com/playfulsparkle/robotstxt.js (opens in new window).
Key Features and Benefits:
- Lightweight and efficient: Designed for minimal overhead and fast processing.
- JavaScript-based: Seamlessly integrates into web development environments and Node.js applications.
Useful for tasks like:
- Programmatically checking if a specific URL is disallowed for a particular user agent: This allows you to build custom logic based on robots.txt rules.
- Building custom robots.txt analysis tools: You can use robotstxt.js to create tools that automatically validate and identify potential issues in robots.txt files.
- Integrating robots.txt parsing into other JavaScript applications: For example, you might want to incorporate robots.txt awareness into your own web scraping or crawling tools.
To truly understand a website's accessibility for search engines, a robots.txt parser (opens in new window) plays a vital role. For instance, the Playful Sparkle SEO Audit (opens in new window), a lightweight SEO audit tool available as a browser extension, actively incorporates this technology.
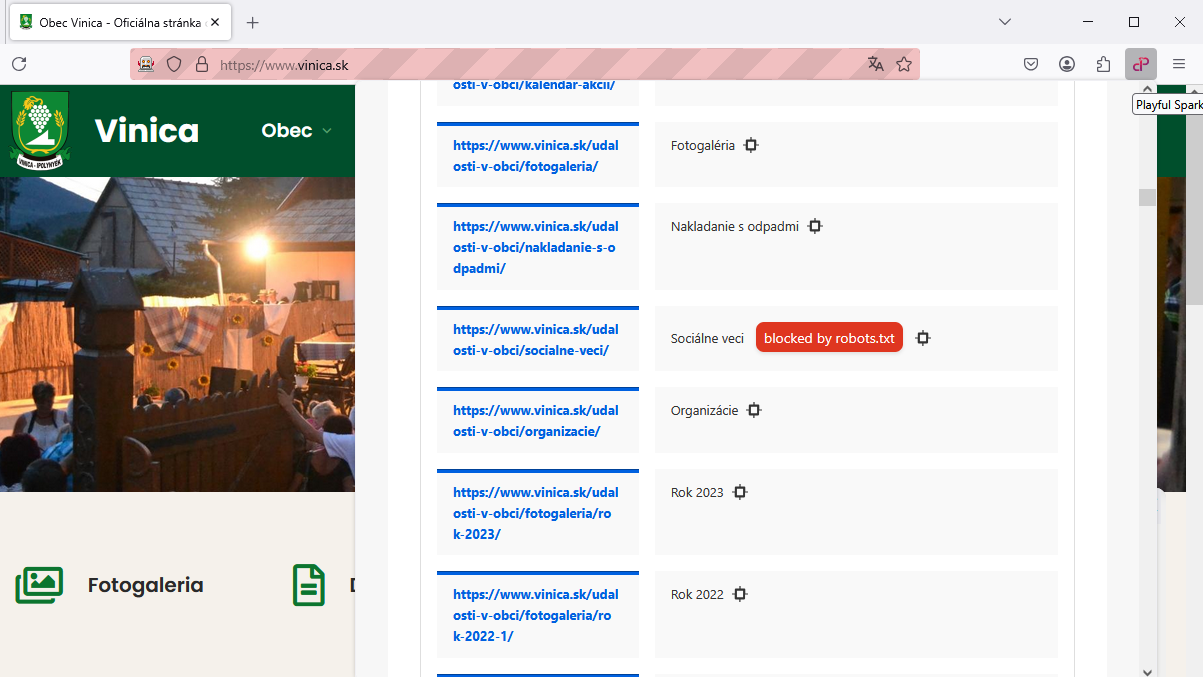
By analyzing the robots.txt file of a website, the extension can determine if the URL of the webpage you're currently viewing is intentionally blocked from search engine crawlers. This provides valuable, non-intrusive insights into potential issues affecting the website's visibility, user engagement, and overall performance in search results.
Implementing Robots Meta Tags and X-Robots-Tag
While robots.txt controls crawling at the website level, you can also control indexing and following of links at the page or individual resource level using robots meta tags and the X-Robots-Tag.
- Robots Meta Tags: (
<meta name="robots" content="...">): These are placed within the<head>section of an HTML page and provide instructions to search engine crawlers on how to handle that specific page. Common values for the content attribute include:noindex:Prevents the page from being indexed.nofollow:Prevents search engines from following any links on the page.noindex, nofollow:Combines both directives.index, follow:The default behavior, explicitly allowing indexing and following.none:Equivalent to noindex, nofollow.all:Equivalent to index, follow.
<head> <meta name="robots" content="noindex"> </head> X-Robots-Tag: This is an HTTP header that provides similar control over indexing and following for non-HTML resources like PDF files, images, and videos. It can also be used for HTML pages.
Example (in your server configuration file, e.g., .htaccess for Apache):<FilesMatch "\.(pdf|jpg|jpeg|png)$"> Header set X-Robots-Tag "noindex" </FilesMatch>
Differences between Robots.txt, Robots Meta Tags, and X-Robots-Tag
- Robots.txt: Controls which parts of your website crawlers can access. It's a website-level directive.
- Robots Meta Tags: Control how individual HTML pages should be indexed and whether links on them should be followed. It's a page-level directive.
X-Robots-Tag: Provides similar control to robots meta tags but can be used for non-HTML resources and is implemented at the HTTP header level.
These methods work in conjunction to give you granular control over how search engines interact with your website content.
Best Practices for Robots.txt
- Keep it Simple: Avoid unnecessary complexity in your robots.txt file. Use clear and concise directives.
- Test Thoroughly: Use tools like Google Search Console's robots.txt Tester to ensure your file is correctly formatted and achieves your intended goals.
- Be Specific: Target the crawlers and content you intend to control. Avoid broad disallows that might accidentally block important pages.
- Don't Use Robots.txt to Hide Sensitive Information: As it's publicly accessible, it's not a security measure. Use proper authentication and authorization methods for sensitive data.
- Link to Your Sitemap: Make it easy for search engines to find all your important pages by including the
Sitemapdirective. - Review Regularly: As your website evolves, review and update your robots.txt file to ensure it still aligns with your SEO strategy.
- Place it in the Root Directory: Ensure the robots.txt file is located in the root directory of your domain.
- Use Comments: Add comments using the
#symbol to explain the purpose of specific directives, especially in more complex files.
Common Mistakes to Avoid with Robots.txt
- Accidentally Blocking Important Content: This is a critical error that can prevent search engines from indexing your valuable pages, leading to a significant drop in organic traffic. Double-check your
Disallowrules. - Using Incorrect Syntax: Even a small typo in the syntax can cause the robots.txt file to be misinterpreted or ignored by search engines. Pay close attention to spelling and formatting.
- Not Testing Changes: Deploying a new or modified robots.txt file without testing can lead to unintended consequences. Always use testing tools before making changes live.
- Assuming Complete Secrecy: Remember that robots.txt is a public file. Don't rely on it to hide confidential information.
- Blocking All Bots: Accidentally using
Disallow: /for all user agents will prevent all search engines from crawling your entire website. - Forgetting the Sitemap Directive: Failing to include the
Sitemapdirective can make it harder for search engines to discover all your important pages.
Identifying and Fixing Robots.txt Warnings and Issues
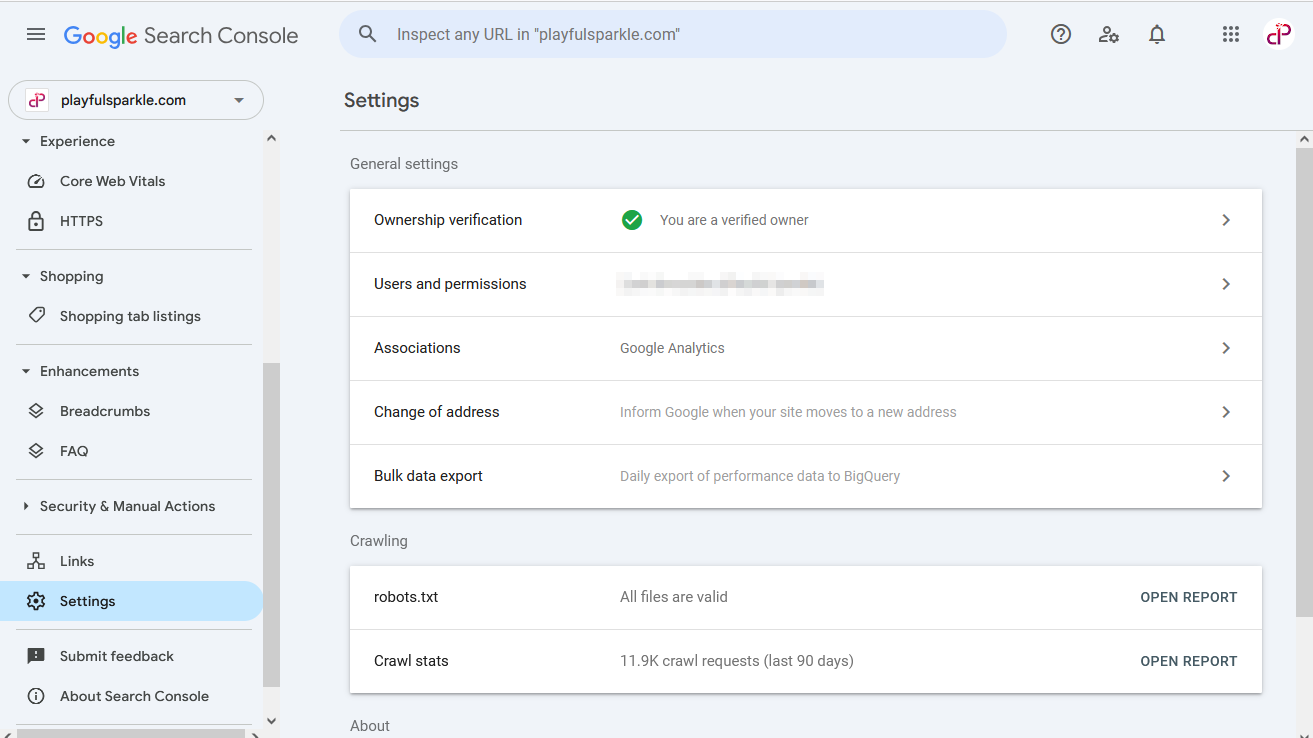
Google Search Console is an invaluable tool for identifying and fixing issues related to your robots.txt file.
How to Identify Robots.txt Issues
- Go to your Google Search Console account.
- Select your website property.
- Navigate to Settings in the left-hand sidebar.
- Under the Crawling section, you will find a row indicating the status of your robots.txt file (e.g., "robots.txt - All files are valid").
- Clicking on this row will open a report providing details about your domain's robots.txt files, including any identified issues or warnings. This report allows you to review the content of your robots.txt file and see if Googlebot is encountering any problems interpreting it.
Common Warnings and Their Solutions
- "Blocked by robots.txt": This warning in the Coverage report (accessible via the Index section) indicates that some of your pages are being blocked from crawling. Investigate whether this is intentional. If important pages are blocked, review your Disallow rules and make necessary adjustments.
- Syntax Errors: The robots.txt report in the Crawling section will highlight any syntax errors in your file. Correct these errors to ensure your directives are properly understood by search engines.
- Incorrect File Location: If Google Search Console indicates an issue with your robots.txt file, ensure it is named exactly robots.txt (lowercase) and placed in the root directory of your website.
Troubleshooting Steps
- Carefully review your
DisallowandAllowrules within the robots.txt report to ensure they are targeting the intended content and user agents. - Check if you have accidentally blocked important CSS or JavaScript files, which can prevent Googlebot from rendering your pages correctly (this might be indicated in the Coverage report or through other testing).
- If you've made changes to your robots.txt file, allow some time for search engines to recrawl and recognize the updates. You can also request indexing of specific URLs in Google Search Console if they were previously blocked and are now allowed.
Can I Block Rogue Bots with Robots.txt?
Yes, you can potentially block rogue bots by targeting their specific User-agent strings in your robots.txt file. As rogue technology advances, various rogue bots are being developed for different purposes, including content generation, research, and analysis.
Importance of Identifying the Correct User-agent
To block a specific rogue bot, you need to know its exact User-Agent string. This information is usually provided by the developers of the rogue bot. You can then add a Disallow directive targeting that specific user agent.
Example: If you want to block a hypothetical rogue bot with the user-agent "RogueBot-Example":
User-agent: RogueBot-Example
Disallow: /This would prevent the "RogueBot-Example" from accessing your entire website.
Considerations and Potential Limitations
- User-agent Spoofing: Some rogue bots might not strictly adhere to their declared user-agent or might even try to spoof other user agents (like Googlebot) to gain access.
- Evolving User-agents: The user-agent strings of rogue bots can change over time, so you might need to update your robots.txt file periodically to maintain the desired blocking.
- Discovery Challenges: Identifying all the relevant rogue bot user-agents can be challenging as the landscape of rogue technology is constantly evolving.
While robots.txt can be a first line of defense against unwanted rogue bot traffic, it might not be a completely foolproof solution. You might need to explore other methods like rate limiting or IP blocking at the server level for more robust control.
Conclusion
The robots.txt file is a fundamental yet powerful tool in the arsenal of any SEO professional or website manager. By understanding its syntax, implementing best practices, and avoiding common mistakes, you can effectively control how search engine crawlers interact with your website, leading to better SEO performance, efficient crawl budget management, and improved overall website health. Remember to test your robots.txt file regularly and adapt it as your website evolves to ensure continued optimal performance.
Don't risk misconfiguring your `robots.txt` and potentially harming your SEO! Maximize your crawl efficiency and SEO potential by letting our experts implement and optimize your robots.txt file. Contact us today to unlock the full potential of your website's search engine visibility.
Questions
It must be located in the root directory of your website (e.g., https://www.yourdomain.com/robots.txt).
Simply type your website's domain name followed by /robots.txt in your web browser's address bar (e.g., yourdomain.com/robots.txt). If a file exists, you will see its contents.
You can create a plain text file named robots.txt using a text editor and then upload it to the root directory of your website via FTP or your hosting provider's file manager.
Follow the same method as checking your own: type the website's domain followed by /robots.txt in your browser.
No, robots.txt is a set of guidelines or requests, not a legal requirement. While most reputable search engines and bots will respect these directives, there's no legal obligation for them to do so.
Yes, robots.txt remains a crucial tool for controlling crawler access and optimizing your website for search engines.
robots.txt:Controls website-wide crawler access.meta robots tag:Controls indexing and link following for individual HTML pages.X-Robots-Tag:Controls indexing and link following for non-HTML resources and can also be used for HTML pages via HTTP headers.
You need to access the robots.txt file on your web server. You can typically do this through an FTP client or a file manager provided by your web hosting provider. Download the file, edit it in a text editor, and then re-upload it to the root directory, overwriting the existing file.
Resources
- Google robots.txt specifications (opens in new window)
- Yandex robots.txt specifications (opens in new window)
- Sean Conner:
An Extended Standard for Robot Exclusion
(opens in new window) - Martijn Koster:
A Method for Web Robots Control
(opens in new window) - Martijn Koster:
A Standard for Robot Exclusion
(opens in new window) - RFC 7231 (opens in new window),
2616(opens in new window) - RFC 7230 (opens in new window),
2616(opens in new window) - RFC 5322 (opens in new window),
2822(opens in new window),822(opens in new window) - RFC 3986 (opens in new window),
1808(opens in new window) - RFC 1945 (opens in new window)
- RFC 1738 (opens in new window)
- RFC 952 (opens in new window)

Article author Zsolt Oroszlány
CEO of the creative agency Playful Sparkle, brings over 20 years of expertise in graphic design and programming. He leads innovative projects and spends his free time working out, watching movies, and experimenting with new CSS features. Zsolt's dedication to his work and hobbies drives his success in the creative industry.
Let’s amplify your success together!
Request a Free QuoteRelated articles

What Is Search Engine Optimization (SEO)?
As seasoned marketing professionals operating within today's rapidly evolving digital environment, you recognize the paramount importance of Search Engine Optimization (SEO). Read moreabout What Is Search Engine Optimization (SEO)?

Ensure your SEO strategy is ready for 2025
In today's digital age, maintaining a strong online presence is crucial, making it essential to keep your SEO strategies dynamic and forward-looking. Read moreabout Ensure your SEO strategy is ready for 2025

Local SEO: A Comprehensive Guide
Local SEO refers to the process of optimizing your online presence to attract more business from relevant local searches. This means that when potential customers search for products or services in their local area, your business should appear prominently in the search results. Read moreabout Local SEO: A Comprehensive Guide